10 Teorin bakom: Hypotesprövning
Tänk dig att du kan läsa, men bara för att du lärt dig hur olika ord ser ut. Du kan inget om logiken bakom; vad bokstäverna heter eller hur man ljuder ihop dem till ord. Men du har memorerat hundratals – om inte tusentals – ord till utseendet. Den här strategin kommer säkert att funka relativt bra, ända tills du stöter på ett nytt ord som du inte sett förut. Men om du istället känner till den underliggande logiken så kan du därefter läsa precis vad som helst under resten av ditt liv.
Det här kapitlet handlar just om den underliggande logiken bakom statistisk inferens. I kapitel 8 introducerade vi några viktiga koncept och idéer; i kapitel 9 grundade vi med en repetition av sannolikhetsläran från skoltiden. Nu gräver vi djupare, lär oss ljuda ihop bokstäverna. Men låt oss börja med en kort repetition: Vad är egentligen den centrala idén bakom hypotesprövning? Jo, den är inte svårare än att den kan sammanfattas på några rader:
Vi ser ett mönster i data. Frågan: Är det verkligt? Eller kan det bortförklaras med “slumpen”? H0 (nollhypotesen): Det finns inget där egentligen (inget samband, ingen effekt, inget mönster) H1 (mothypotesen): Det finns nåt där (ett samband, en effekt, ett mönster) Principen: Vi utgår från att nollhypotesen är korrekt (det finns inget där egentligen): Hur pass sannolikt är det då att få ett så pass tydligt mönster i data som det vi observerar? Är den sannolikheten liten? Ja, det skulle då tyda på att nollhypotesen är falsk. Vi säger då att vi förkastar nollhypotesen eller att resultatet är signifikant. |
Låt oss omsätta den här principen i praktiken genom att se på några tillämpningar.
23. Teorin bakom statistisk inferens, del 1
24. Teorin bakom statistisk inferens, del 2
10.1 Principen bakom
Exempel. En magiker har ett mynt. Vi vill ta reda på om myntet är riggat: Landar det faktiskt krona upp i 50 procent av fallen i långa loppet?
Vi konstruerar därför följande försök: Vi kastar myntet totalt 400 gånger. Om fördelningen av krona och klave blir osannolikt skev så drar vi slutsatsen att det faktiskt är nåt skumt med myntet.
Men vad vore då en “osannolikt skev” fördelning? Om vi får exakt 200 krona och 200 klave så finns det förstås ingen orsak att misstänka fuffens. Om fördelningen är 201/199 … nej, fortfarande ingen orsak att misstänka fuffens, och detsamma gäller fördelningarna 202/198 eller 203/197 … allt det här är ju sådant som enkelt kan inträffa bara av slumpen. Men i något skede blir fördelningen förstås så pass skev att vi börjar bli misstänksamma. När sker det? Det finns ingen magisk “korrekt” gränsdragning, men följande visar hur man oftast brukar resonera: Om myntet egentligen inte är riggat, så kommer vi att få någonting mellan 181 och 219 stycken krona med 95-procentig sannolikhet. Det här illustreras i figuren nedan. Detta är en binomialfördelning där “antalet krona” ~ Bin(400; 0,5). Det gröna området visar var vi kommer att landa med 95-procentig sannolikhet givet att myntet inte är riggat. Om vi får fler – eller färre – antal krona än detta, så finns det stöd för att påstå att det faktiskt är nåt lurt med myntet.
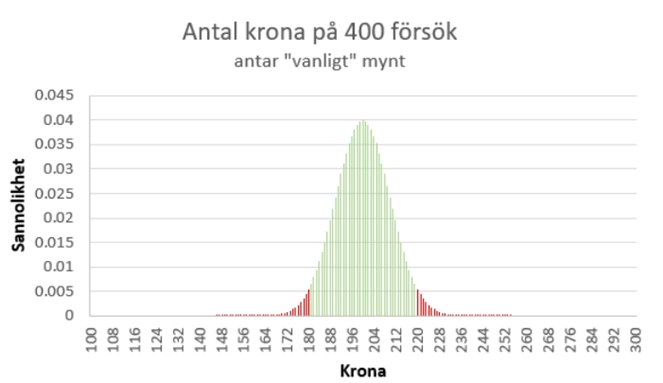
Anta nu att vi utför vårt försök – singlar slanten 400 gånger – och får 250 stycken krona. Det här är alltså ett ovanligt skevt resultat om myntet faktiskt inte är riggat. I figuren ovan ligger vi långt till höger i den “röda regionen”. Så hur pass “extremt” är det här resultatet? Jo, 250 stycken krona hör till de 0,000065 procent extremaste resultaten vi kan få bara av slumpen:
P(antal krona ≥ 250 | myntet ej riggat) + P(antal krona ≤ 150 | myntet ej riggat) = 0,00000065
Vi kan därför dra slutsatsen att myntet faktiskt är riggat. Om det inte är riggat så har vi råkat få ett högst osannolikt resultat – en så pass skev fördelning att detta bara inträffar i 0,000065 procent av fallen i långa loppet.
Låt oss se på vad som just hände i det här exemplet. Vi ställde upp noll- och mothypotesen:
H0: Myntet är inte riggat, dvs. p = 0,5
H1: Myntet är riggat, dvs. p ≠ 0,5
där p betecknar sannolikheten för att myntet landar ‘krona upp’ vid ett försök. Vi utgick från att nollhypotesen är sann, och beräknade sannolikheten för att få minst 250 (eller max 150) stycken krona på 400 försök. Det här är vårt p-värde som blev 0,00000065. P-värdet säger alltså att vårt experiment hör till de 0,000065 procent mest extrema som man kan få bara av slumpen. Resultatet är alltså signifikant: Vi brukar ju dra gränsen vid 5 procent. I detta fall är resultatet också signifikant på 1-procentsnivån, ty p-värdet < 0,01.
Det här exemplet visar också att statistisk inferens och domstolar har något gemensamt: Du är oskyldig tills motsatsen bevisats. I statistiktermer: Vi håller fast vid nollhypotesen – inget samband, ingen effekt, inget mönster – tills dess att data talar tillräckligt starkt emot. I detta exempel talade data tillräckligt starkt emot. Men så är det förstås inte alltid – ibland lyckas vi inte förkasta nollhypotesen. Det betyder inte att vi uttryckligen påstår att nollhypotesen är sann – att myntet inte är riggat – utan bara att vi inte har tillräckliga bevis för att påstå motsatsen. Eller med andra ord: Vi påstår då inget alls.
Hur ofta behöver vi då den här typen av tester som bygger på binomialfördelningen? Det är kanske inte så vanligt att vi vill testa huruvida ett mynt är riggat eller inte. Men tester gällande andelar (p) förekommer förstås en hel del och i dessa fall kan vi utnyttja binomialfördelningen. Låt oss därför se på ännu ett exempel.
Exempel. Emily Rosa är den yngsta personen att – vid 12 års ålder – publicera en artikel i en akademisk journal (JAMA). Studien gick ut på att testa om TT funkar, där TT är kort för ‘therapeutic touch’. Utövare påstår att de kan känna av människans energifält. Så kan de? I studien ingick flera utövare och upplägget var följande: En utövare stack in sina armar i varsitt hål i ett skynke. På andra sidan satt Emily Rosa. Hon valde sedan slumpmässigt att lägga sin ena hand ovanför utövarens vänstra eller högra hand. Utövaren skulle sedan avkänna energifältet för att säga vilken. Totalt utfördes 150 försök1. Emily Rosa ställde upp följande noll- och mothypotes:
H0: TT funkar inte, dvs. p = 0,5
H1: TT funkar, dvs. p > 0,5
där p betecknar sannolikheten för att en utövare får rätt.
Notera att mothypotesen nu inte innefattar möjligheten att p < 0,5, dvs. att TT-utövare skulle vara systematiskt sämre än slumpen på att gissa rätt hand. Man kallar därför detta för ett ensidigt test. Dessa passar bra om man tänker sig att ett alternativ är mer eller mindre otänkbart eller helt ointressant. Här tänker sig Emily Rosa alltså att det är otänkbart eller ointressant att p skulle vara mindre än 0,5. Motsatsen till ett ensidigt test är ett tvåsidigt test, vilket här skulle ha betytt att p ≠ 0,5 enligt mothypotesen.
Anta att TT-utövarna gissade rätt i 90 fall på 150 försök. Nyckelfrågan: Hur stor är sannolikheten för minst 90 rätt på 150 försök om vi utgår från att nollhypotesen är korrekt?
p-värdet = P(X ≥ 90 | p = 0,5)
Notera nu att vi beräknar p-värdet ensidigt, dvs. vi beräknar bara sannolikheten för 90 rätt eller fler. Det här beror på att vår mothypotes är ensidig. Kalylatorn nedan visar att det sökta p-värdet är 0,0088:
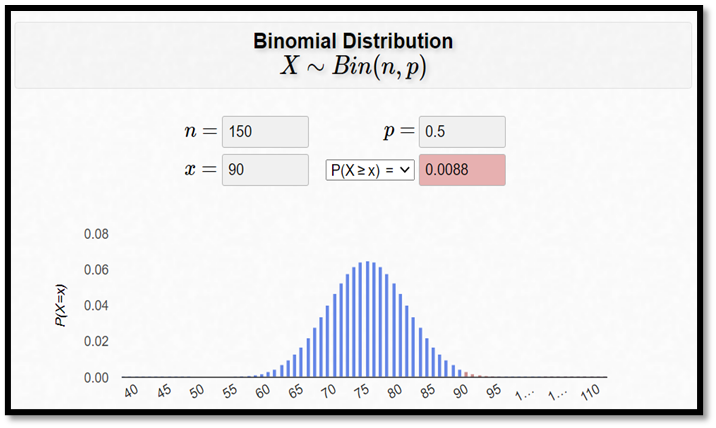
Vi skulle då kunna förkasta nollhypotesen på 1-procentsnivån (p-värdet < 0,01). Eller med andra ord: Data stödjer då idén om att TT-utövarna är bättre slumpen. Att få minst 90 rätt på 150 försök kanske inte låter så fruktansvärt imponerande, men det är likväl högst osannolikt givet att p = 0,5.
Egentligen var TT-utövarna dock inte så här duktiga. De gissade bara rätt i 70 fall på 150 försök. P-värdet blir då 0,815:
p-värdet = P(X ≥ 70 | p = 0,5) = 0,815
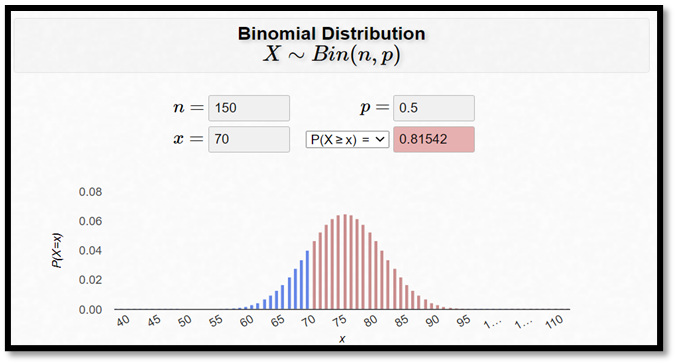
Eller med andra ord: Det finns inget stöd i data för att TT-utövarna skulle vara bättre än slumpen.
Emily Rosa och hennes medförfattare drog slutsatsen: “To our knowledge, no other objective, quantitative study involving more than a few TT practitioners has been published, and no well-designed study demonstrates any health benefit from TT. These facts, together with our experimental findings, suggest that TT claims are groundless and that further use of TT by health professionals is unjustified.” Klippt från A Close Look at Therapeutic Touch (1998), Journal of the American Medical Association.
Notera här att författarna inte påstår att TT är verkningslöst. Det kan man strikt taget inte göra med hjälp av statistik. Vi kan alltså inte visa att nollhypotesen är sann. Däremot kan vi säga att det inte finns något stöd för att mothypotesen skulle vara sann.
De här två exemplen beskriver idén bakom hypotesprövning. Och den här idén återanvänds i all hypotesprövning, oavsett om din hypotes gäller en andel (p) eller något annat, t.ex. ett populationsmedelvärde (µ) eller en regressionskoefficient (β). Men då kan vi inte längre utnyttja binomialfördelningen för att beräkna p-värdet. Vi ska nu se hur vi då istället kan gå tillväga.
Exempel. I befolkningen överlag ligger den genomsnittliga IQ-nivån på 100 med en standardavvikelse på 15. Vi vill ta reda på om brottslingar har en IQ-nivå som skiljer sig från befolkningen överlag:
H0: Brottslingars genomsnittliga nivå skiljer sig inte från övriga, dvs. µ = 100.
H1: Brottslingars genomsnittliga nivå skiljer sig från övriga, dvs. µ ≠ 100.
Vi har slumpmässigt samplat 100 brottslingar. Anta att brottslingarnas genomsnittliga IQ-nivå ligger på 94 poäng i samplet (\(\overline{x} = 94)\). Vi vill då veta: Hur stor är sannolikheten för att få ett så här pass avvikande resultat om µ egentligen är 100? Eller med andra ord: Hur stor är sannolikheten för att få ett sampel där stickprovsmedelvärdet blir 94 eller mindre, alternativt 106 eller större, om brottslingarnas sanna medelvärde är 100?
\[ p\text{-värdet} \;=\; P\!\left(\overline{X} \leq 94 \;\middle|\; \mu = 100\right) \;+\; P\!\left(\overline{X} \geq 106 \;\middle|\; \mu = 100\right) \]
Om vi tänker oss att nollhypotesen är korrekt och att brottslingarnas intelligenskvot också har en standardavvikelse på 15 (precis som i befolkningen överlag) så får vi medelvärdet och standardavvikelsen i samplingfördelningen för stickprovsmedelvärdet som:
\[\mu_{\overline{x}} = \mu = 15\]
\[\sigma_{\overline{x}} = \frac{\sigma}{\sqrt{n}} = \frac{15}{\sqrt{100}} = 1,5\]
I det här skedet kan vi räkna ut att sannolikheten för att få ett sampel där stickprovsmedelvärdet hamnar minst 6 poäng “snett” är 0,00006:
\[ P\!\left(\overline{X} \leq 94 \;\middle|\; \mu = 100\right) + P\!\left(\overline{X} \geq 106 \;\middle|\; \mu = 100\right) = P(Z \leq -4) + P(Z \geq 4) \]
\[ = 0,00003 + 0,00003 = 0,00006 \]
\[ \text{där } z = \frac{94 - 100}{1,5} = -4 \quad \text{och} \quad z = \frac{106 - 100}{1,5} = 4 \]
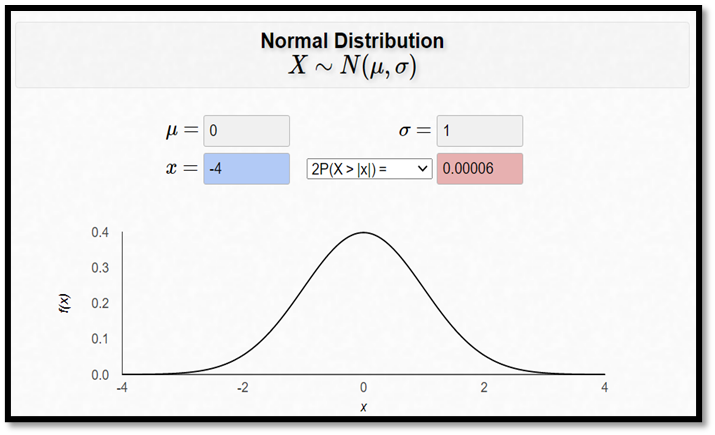
Brottslingarna har alltså signifikant lägre IQ än befolkningen överlag. De ligger 6 poäng under i snitt, och denna skillnad är signifikant på 1-procentsnivån (ty 0,00006 < 0,01).
Ensidiga tester eller tvåsidiga?
Innan vi går vidare ska vi helt kort stanna upp vid frågan om ensidiga kontra tvåsidiga tester. Vilket ska man använda i praktiken? Svaret är att du högst antagligen vill använda ett tvåsidigt test (det är det klart vanligaste). Det här beror på att avvikelser från nollhypotesen nästan alltid är intressanta, oavsett om de är positiva eller negativa. Exempel: Brottslingar skulle ju kunna vara smartare än befolkningen överlag och det vore också ett intressant fynd! Men med en ensidig mothypotes, H1: µ < 100, så skulle vi aldrig kunna komma till den slutsatsen.
Det viktigaste är dock att aldrig ändra strategi utifrån data. Om vi mäter brottslingarnas IQ, finner att de snittar under 100 och då bestämmer oss för att göra ett ensidigt test, H1: µ < 100, så blir p-värdet faktiskt fel. Då kommer vi, i långa loppet, att förkasta nollhypotesen för ofta.2
10.2 T-testet
Exempel. I ett experiment låter man 25 elever skriva ett kunskapsprov vid läsårets slut. Därefter skriver de motsvarande prov efter sommarlovet. För varje elev mäter vi sedan skillnaden i antalet poäng (efter minus före). Idén är att testa om nivån håller i sig under sommarlovet:
H0: Det finns ingen genomsnittlig skillnad i resultat, µ = 0
H1: Det finns en genomsnittlig skillnad i resultat, µ ≠ 0
där µ är den sanna genomsnittliga skillnaden i resultat. Bland de 25 eleverna har dock resultatet i snitt sjunkit med 3 poäng under sommarlovet (\(\overline{x} = - 3)\) med en standardavvikelse på 6 poäng (s = 6). Men är det här en signifikant nedgång? Eller med andra ord: Hör det till de 5 procent extremaste resultat som man kan få om nollhypotesen är sann? Vi skulle alltså vilja beräkna:
\[ p\text{-värdet} = P\!\left(\overline{X} \leq -3 \;\middle|\; \mu = 0\right) + P\!\left(\overline{X} \geq 3 \;\middle|\; \mu = 0\right) \]
Men i detta fall har vi inte tillräckligt med information för att kunna göra exakt den här beräkningen. För att beräkna ovanstående p-värde så skulle vi först vilja ta reda på z-värdet: en avvikelse med 3 poäng, hur mycket är det uttryckt i standardavvikelser? Men denna standardavvikelse är okänd för oss:
\[z = \frac{\overline{x} - \mu}{\sigma_{\overline{x}}} = \frac{- 3 - 0}{\color{red}?}\]
\[\sigma_{\overline{x}} = \frac{\sigma}{\sqrt{n}} = \frac{\color{red}?}{\sqrt{n}}\]
I IQ-exemplet antog vi att \(\sigma\) var 15 och kunde då räkna ut z-värdet. Men i vanliga fall har vi inte tillgång till någon sådan information – vi har ju bara vårt sampel. Så låt oss helt sonika ersätta \(\sigma\) med samplets standardavvikelse, s, som här var 6 poäng:
\[\sigma_{\overline{x}} = \frac{\sigma}{\sqrt{n}} \approx\]
\[s_{\overline{x}} = \frac{s}{\sqrt{n}} = \frac{6}{\sqrt{25}} = 1,2\]
När vi nu ersatt \(\sigma_{\overline{x}}\) med \(s_{\overline{x}}\) får vi istället det som kallas för t-värdet:
\[t = \frac{\overline{x} - \mu}{s_{\overline{x}}} = \frac{- 3 - 0}{1,2} = - 2,5\]
Du torde känna igen t-värdet, det är effekten delat med standardfelet, \(s_{\overline{x}}\). I detta fall får vi ett t-värde på -2,5 – ett signifikant resultat med andra ord, ty -2,5 är mindre än -2. Men om vi vill räkna ut det exakta p-värdet så behöver vi veta mer än denna tumregel. I det här exemplet ges p-värdet av:
\[ P(T \leq -2,5) + P(T \geq 2,5) = 0,01966 \]
Hur har vi kommit fram till denna sannolikhet? Även om z-värdet och t-värdet liknar varandra mycket, så följer de inte exakt samma fördelning. Eller med andra ord: T-statistikan följer inte en standardiserad normalfördelning. T-statistikan följer istället en så kallad t-fördelning givet att \(\overline{x}\) följer en normalfördelning (vilket vi kan anta vara fallet här, åtminstone ungefärligt, tacka centrala gränsvärdessatsen!).
Så vad är en t-fördelning? Jo, t-fördelningen ser ut som en standardiserad normalfördelning, bara att den har lite tjockare svansar. Ju större sampel, desto mer liknar t-fördelningen en standardiserad normalfördelning. Det här innebär att t-fördelningen ser lite olika ut beroende på samplets storlek. Vi anger vilken t-fördelning det är frågan om genom en parameter som kallas för frihetsgradsantalet. Då vi gör tester gällande ett medelvärde så ges frihetsgradsantalet av antalet observationer minus ett:
\[ \text{frihetsgraderna} = n - 1 \]
I vårt exempel har t-fördelningen alltså 24 frihetsgrader (vi samplade ju 25 elever). Hur ser t-fördelningen med 24 frihetsgrader ut? Nedan visas denna t-fördelning och z-fördelningen i samma figur.
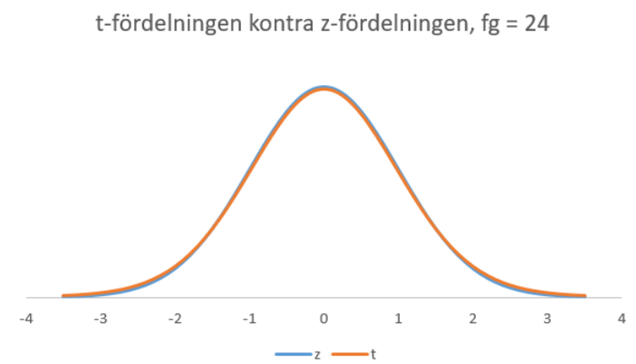
Som du märker är dessa fördelningar mycket lika varandra. Men man kan ändå ana att p-värdet blir aningen större med t-fördelningen än med z-fördelningen. För att beräkna p-värdet (utifrån t-fördelningen) har jag här använt följande kalkylator.
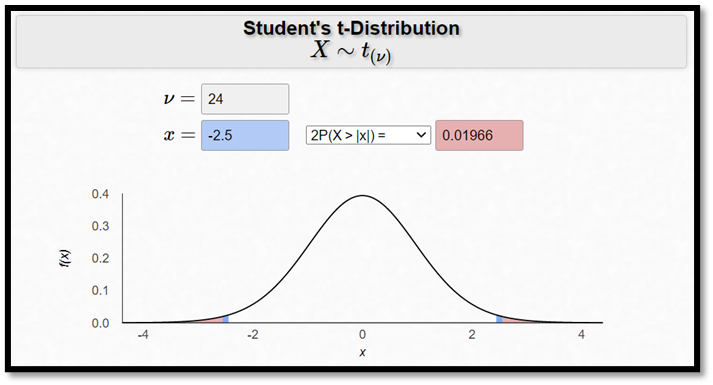
där v är frihetsgraderna. (En brasklapp: Den här kalkylatorn kallar t-fördelningen för “Student’s t-distribution”. Det beror inte på att kalkylatorn är gjord för att användas av studenter, utan för att t-fördelningen i början härleddes av en statistikstuderande. När han först publicerade sitt resultat gick han blygsamt under pseudonymen “A Student of Statistics”. Sen har t-fördelningen ibland kallats för Student’s t-distribution. Hans egentliga namn var William Gosset.)
I praktiken jobbar vi oftast med ännu större sampel, och då liknar t- och z-fördelningen varandra ännu mer. Då har det sällan någon praktiskt betydelse vilken av dessa vi använder. Men när vi har datorer till vår hjälp så kan vi lika bra göra rätt och använda t-fördelningen (det kostar ju ingenting).
Exempel forts. I kapitel 8 lärde du dig om hur man kan göra upp ett ungefärligt 95-procentigt konfidensintervall genom att ta estimatet plus/minus två standardfel. Men hur får man det exakta konfidensintervallet? Jo, detta ges av:
\[\text{estimatet} \;\pm\; (\text{kritiskt värde} \times \text{standardfelet})\]
Om vi gör upp ett konfidensintervall för ett populationsmedelvärde har vi alltså:
\[\overline{x} \pm c \times s_{\overline{x}}\]
där c betecknar det kritiska värdet. Så vad är det kritiska värdet? Jo, anta i detta fall att vi hade fått ett p-värde på exakt 0,05. Vilket t-värde hade vi då fått? Jo, ett t-värde på -2,0639 alternativt 2,0639. Detta är de kritiska värdena på 5-procentsnivån. Du kan se det genom att använda samma online-kalkylator som senast:
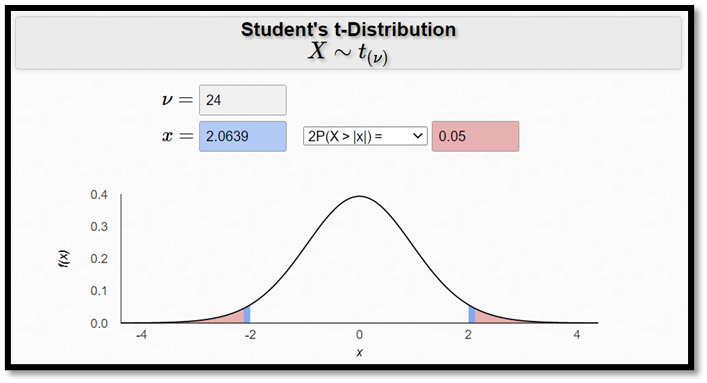
Låt oss ta det positiva kritiska värdet. Då får vi konfidensintervallet som:
\[- 3 \pm 2,0639 \times 1,2\]
så att intervallet ges av (-5,48; -0,52). Populationsmedelvärdet – alltså hur elevernas kunskaper egentligen förändrades under sommarlovet – ligger alltså någonstans inom detta intervall med 95-procentig säkerhet. Vi kan se att denna formel ger oss ett 95-procentigt konfidensintervall på följande sätt:
Sannolikheten för att t-statistikan ligger inom de kritiska gränserna är 0,95:
\[P( - 2,0639 \leq T \leq 2,0639) = 0,95\]
\[P\left( - 2,0639 \leq \frac{\overline{x} - \mu}{s_{\overline{x}}} \leq 2,0639 \right) = 0,95\]
Stuvar om inom parentesen:
\[P\left( \overline{x} - 2,0639 \times s_{\overline{x}} \leq \mu \leq \overline{x} + 2,0639 \times s_{\overline{x}} \right) = 0,95\]
För att få ett 90-procentigt konfidensintervall ska vi alltså på motsvarande sätt hitta det kritiska värdet på 10-procentsnivån, dvs. det t-värde som ger oss ett p-värde på 0,1. Och för att få ett 99-procentigt konfidensintervall ska vi först hitta det kritiska värdet på 1-procentsnivån, dvs. ett t-värde som ger oss ett p-värde på 0,01. I detta exempel är det t-värdet 2,79694:
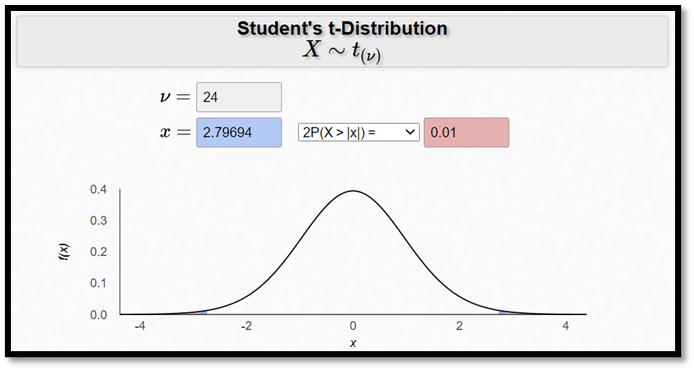
Ett 99-procentigt konfidensintervall ges då av:
\[- 3 \pm 2,79694 \times 1,2\]
10.3 T-testet i regressionsanalys
Vi har nu sett hur t-värdet kan användas för att testa hypoteser gällande medelvärden. Men tidigare har vi också använt t-testet för regressionskoefficienter. Låt oss därför ännu se på ett sådant exempel.
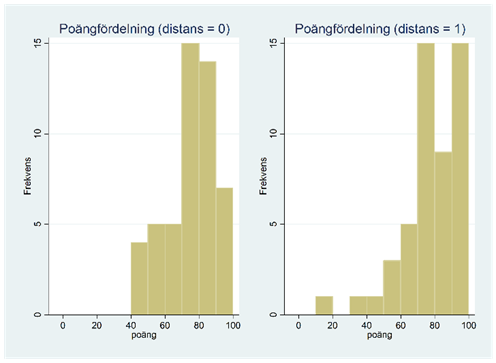
Exempel. Vi vill utvärdera distansundervisning och använder en stor grundkurs vid ÅA till vår hjälp. 100 studenter går kursen, och dessa slumpas in i två jämnstora grupper. Den första gruppen får traditionell salsundervisning och den andra får distansundervisning. Alla skriver samma tentamen i slutet. Nedan visas poängfördelningen i de två grupperna: de som fick traditionell undervisning (distans = 0) och de som fick distansundervisning (distans = 1).
Tabellen nedan sammanfattar data.
| Distans | Medelvärde | Standardavvikelse | Min | Max |
|---|---|---|---|---|
| 0 | 75,06 | 14,98 | 41 | 100 |
| 1 | 77,20 | 17,84 | 11 | 99 |
Distansgruppen har alltså presterat lite bättre än den traditionella gruppen, men är skillnaden signifikant?
H0: Ingen skillnad i medelvärden mellan grupperna, dvs. µ0 = µ1 (eller på regressionsspråk: β = 0)
H1: Det finns en skillnad i medelvärden mellan grupperna, dvs. µ0 ≠ µ1 (eller på regressionsspråk: β ≠ 0)
För att testa om skillnaden mellan grupperna är signifikant så beräknar vi t-värdet, dvs. effekten genom standardfelet. I detta fall har vi en effekt på 2,14, dvs. distansgruppen presterade i snitt 2,14 poäng bättre än den traditionella gruppen:
\[\widehat{poäng} = 75,06 + 2,14 \times distans\]
Vad är standardfelet för den effekten? Tidigare såg vi hur man beräknar standardfelet för ett stickprovsmedelvärde. Här vill vi beräkna standardfelet för skillnaden mellan två medelvärden. Det här är i praktiken lite krångligare att göra manuellt, och vi överlåter det jobbet till datorerna. Som tidigare gäller dock att större sampel ger lägre standardfel (allt annat lika).
Tabellen nedan ger regressionsutskriften klippt ur Excel. Den visar att standardfelet för regressionskoefficienten är 3,29 vilket ger oss ett t-värde på 0,65 (vilket ju också ges i tabellen):
\[t = \frac{2,14}{3,29\ldots} = 0,649\ldots\]
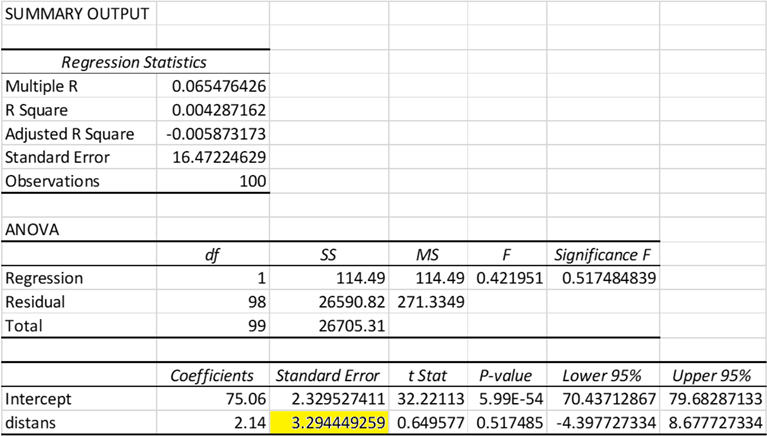
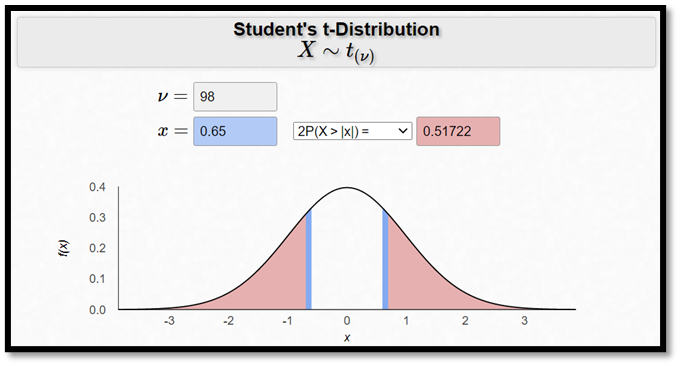
T-värdet är ju ganska litet, så resultatet är inte signifikant. Vi kan också se detta från p-värdet som är långt större än 0,05:
\[p\text{-värdet} = P(T \leq -0,65) + P(T \geq 0,65) = 0,517\]
Med hjälp av kalkylatorn nedan har jag också räknat ut p-värdet utifrån t-värdet. För att lyckas med detta så måste vi först känna till hur många frihetsgrader t-fördelningen har i detta fall. När vi testar hypoteser gällande en regressionskoefficient så ges frihetsgraderna av:
\[ frihetsgrader = n - k - 1 \]
där k är antalet oberoende variabler (här 1). Eftersom vi hade 100 observationer så blir frihetsgraderna då 98 (= 100-1-1).
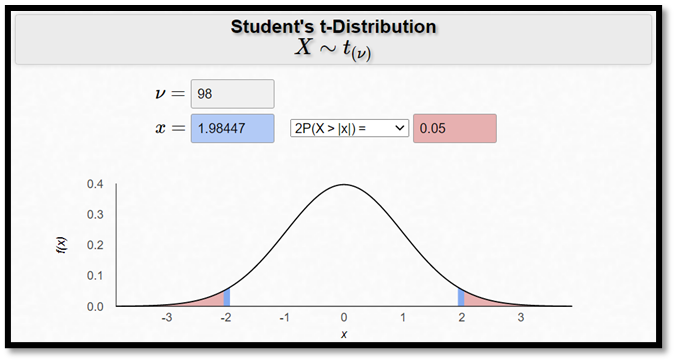
Exempel forts. Gör nu upp ett 95-procentigt konfidensintervall för β.
Konfidensintervallet fås som förut av: estimatet ± kritiska värdet*standardfelet
… där estimatet = 2,14; standardfelet = 3,29… och det kritiska värdet på 5-procentsnivån är 1,98… då vi har 98 frihetsgrader (se kalkylatorn nedan). Detta ger att intervallets nedre gräns är -4,40 och den övre är 8,68. Vi kan bekräfta att beräkningen gått rätt till från Excel-utskriften. Vi kan också notera att värdet 0 ryms inom intervallet – precis det ska – effekten var ju inte signifikant olika 0. Utifrån detta datamaterial finns det alltså inget stöd för att påstå att distansundervisning skulle vara bättre eller sämre än traditionell salsundervisning.
10.4 Antaganden
Om du googlar på “standard error for the difference between group means” eller “standard error for the regression coefficient” så kommer du att se att standardfelet kan beräknas på lite olika sätt, vilket kan ge lite olika resultat. Om man använder fel formel så kan man få ogiltiga resultat (för små eller stora p-värden). Det finns i synnerhet ett fall där detta fel kan bli extra stort: Då vi har beroende dragningar. Låt oss därför fundera lite på vad som menas med det.
Alla de exempel vi tittat på hittills bygger på att vi kan likna samplet vid en samling oberoende dragningar från en urna:

Om dragningarna däremot är beroende så blir våra p-värden generellt sett felaktiga. Exempel: Föreställ dig att vi slumpmässigt drar två bollar från urnan ovan till vänster. Och anta att vi drar bollarna med återläggning (så att vi lägger tillbaka den första bollen innan vi drar den andra). Hur stor är sannolikheten för att vi får två röda bollar? Jo, 25 procent (= 0,5*0,5). Anta nu att vi drar bollarna utan återläggning. Hur stor är nu sannolikheten för att vi får två röda bollar? Jo, 20 procent (= 0,5*0,4). Hur samplet dras spelar alltså roll då vi beräknar sannolikheten för ett visst utfall. Och detsamma gäller i all sorts sampling. Exempel: Sannolikheten för att få ett stickprovsmedelvärde som avviker med minst 6 enheter från populationsmedelvärdet kommer att bero på hur vi drar vårt sampel.
Vad är då skillnaden mellan att dra bollar med och utan återläggning? Jo, när vi drar bollarna med återläggning så är de två utfallen oberoende, dvs. sannolikheten för att få en röd boll i andra dragningen beror inte av den första bollens färg. När vi drar bollarna utan återläggning så är de två utfallen beroende, dvs. sannolikheten för att få en röd boll i andra dragningen varierar beroende på om den första bollen var röd eller blå.
I statistiska undersökningar kan också våra mätningar vara beroende, men då av andra orsaker. Ett sådant fall är om vi har ett klustrat sampel (se kapitel 8). Tidsseriedata kan generellt sett inte heller betraktas som en samling oberoende mätningar. Vi ska inte gå in på hur man hanterar den typen av data, men det är bra att vara medveten om att de klassiska metoder som vi sett på i detta kapitel generellt sett inte lämpar sig för sampel med beroende mätningar.
Övningsuppgifter
Principen bakom
[Kräver online-kalkylator] Är risken för att bli stannad av polisen större om du har ett utländskt registernummer? På en viss sträcka stannar polisen 10 procent av alla bilar. Du vill nu testa om detta också gäller förare med utländska registerplåtar. Bland 200 sådana bilar är det 32 som stannas. Testa:
H₀: p = 0,1
H₁: p ≠ 0,1
där p betecknar sannolikheten för att en utländsk bil ska stannas.
Hur stort blir p-värdet? Kan nollhypotesen förkastas? I så fall, på vilken nivå?
- [Kräver online-kalkylator] Från en dag till en annan så kan aktiekursen antingen stiga eller sjunka. Anta att den stiger med en sannolikhet på 50 procent. Du har dock en hypotes om att denna sannolikhet är högre på måndagar. Under 200 måndagar så har aktiekursen stigit i 58 procent av fallen. Testa om detta är signifikant högre än 50 procent genom ett ensidigt test.
T-testet
[Kräver online-kalkylator] Sover finländare i snitt 8 timmar per dygn? Vi vill testa detta och ställer upp:
H₀: μ = 8
H₁: μ ≠ 8
I ett slumpmässigt sampel omfattande 100 finländare ligger medelvärdet på 7,7 timmar med en standardavvikelse på 0,8 timmar.
Kan nollhypotesen förkastas? I så fall, på vilken nivå?
Beräkna nu också ett 95-procentigt konfidensintervall för μ.
Skulle ett 99-procentigt konfidensintervall innehålla värdet 8? (Besvara frågan utan att räkna ut konfidensintervallet.)
En internetbutik hävdar att det i genomsnitt tar 5 dagar från beställning till leverans för deras produkter. I ett slumpmässigt sampel omfattande 40 produkter så låg leveranstiden på 5,5 dagar med en standardavvikelse på 2 dagar. De kritiska värdena på 10-, 5- och 1-procentsnivån är 1,685, 2,023 och 2,708. Testa:
H₀: μ = 5
H₁: μ ≠ 5
Kan nollhypotesen förkastas? I så fall, på vilken nivå?
Beräkna nu också ett 90-procentigt konfidensintervall för μ.
T-testet i regressionsanalys
- Tar personer som studerar i Helsingfors i snitt ut större studielån än sådana som studerar i Åbo? Vi samplar slumpmässigt 200 studerande från respektive stad och mäter skillnaden mellan grupperna. Anta att Helsingforsborna i snitt tar ut 50 euro mer i studielån per månad, och att standardfelet för den skillnaden är 20 euro. De kritiska värdena på 10-, 5- och 1-procentsnivån är 1,653, 1,972 och 2,601.
Är skillnaden mellan grupperna signifikant? I så fall, på vilken nivå?
Beräkna också ett 95-procentigt konfidensintervall för skillnaden mellan grupperna (β).
[Kräver online-kalkylator] Se regressionen nedan. Den beskriver tentamenspoäng som en funktion av arbetstid (tid), förkunskaper (förk, en dummy som antar värdet 1 för studenter som anser sig ha tillräckliga förkunskaper och annars värdet 0) samt kvinna (en dummy för kvinnor). Standardfel ges inom parentes. Samplet består av 80 studenter.
\[ \widehat{\text{poäng}} = a + \underset{\displaystyle (0,2)}{1,1} \times \text{tid} + \underset{\displaystyle (3,2)}{7,2} \times \text{förk} + \underset{\displaystyle (1,6)}{3,0} \times \text{kvinna} \]
Vilken eller vilka av de tre effekterna är signifikanta? Och i så fall, på vilken nivå? Beräkna p-värdet i respektive fall.
- Vilket eller vilka av följande påståenden gällande hypotesprövning är korrekta?
Om ett resultat inte är signifikant så har vi visat att nollhypotesen är korrekt.
Då nollhypotesen är korrekt så kan vi inte få ett signifikant resultat.
Då nollhypotesen är korrekt så får vi ett signifikant resultat (5-procentsnivån) i 5 procent av fallen i långa loppet.
Då mothypotesen är korrekt så kan vi få ett icke-signifikant resultat, men detta är mindre troligt med stora sampel.
Experimentet upprepades senare en andra gång med ytterligare 130 försök.↩︎
Det här är antagligen också en anledning till att ensidiga tester inte är så populära. Läsaren kan inte veta när du bestämt dig för att testet ska vara ensidigt (före eller efter du såg data) och det kan då verka som att du kanske bara letat efter signifikans.↩︎